TL;DR
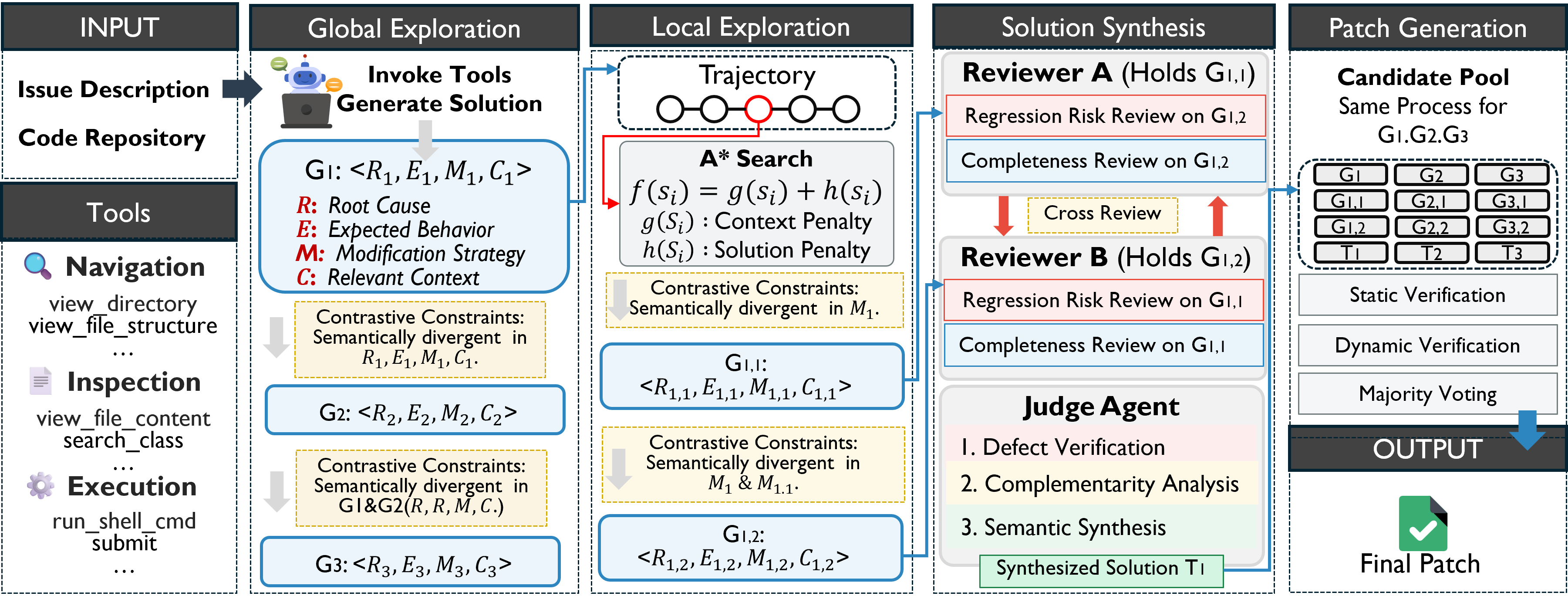
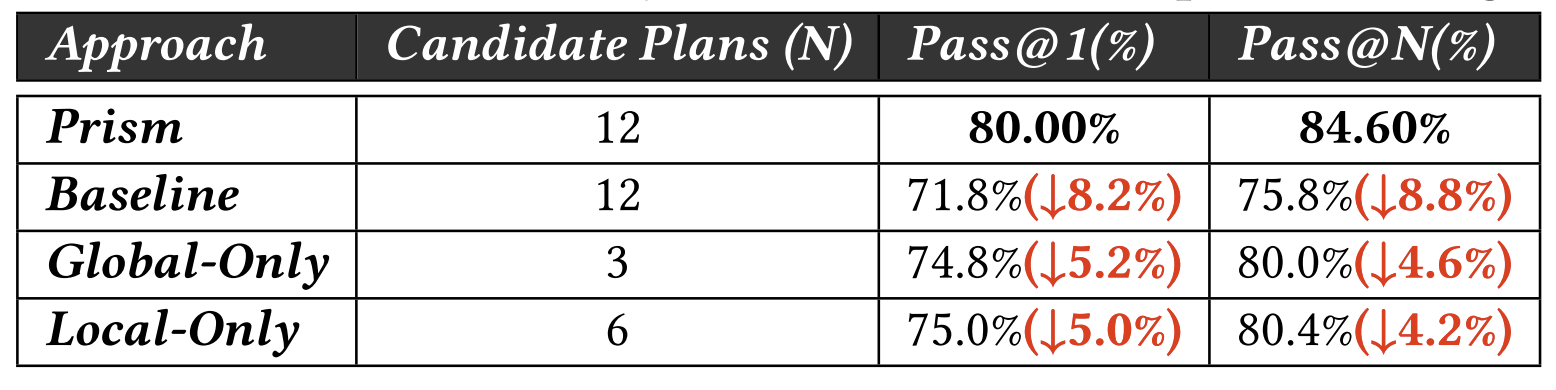
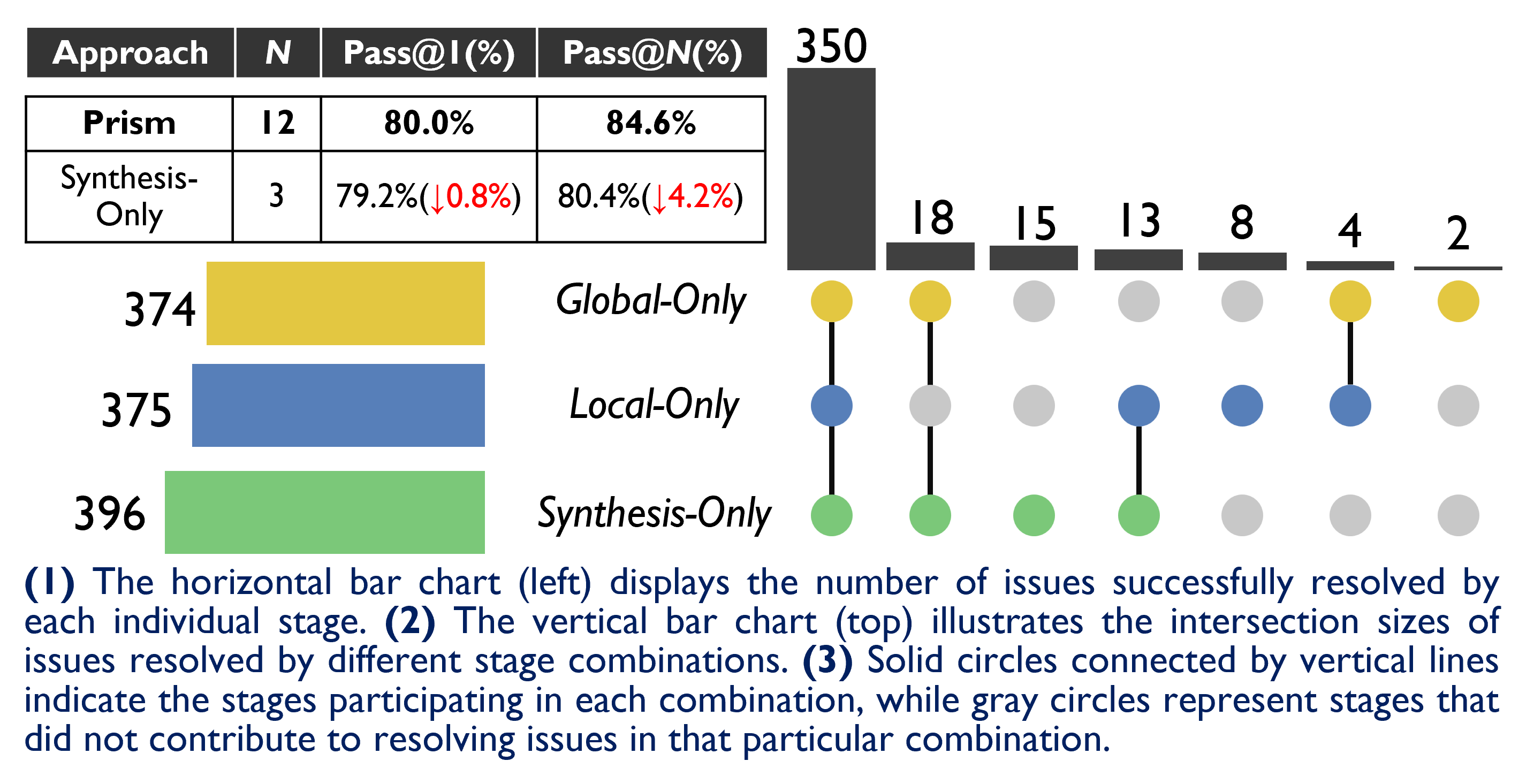
We present Prism, a multi-solution reasoning and synthesis framework for repository-level issue resolution. Existing agents face two critical bottlenecks: limited solution diversity caused by LLM mode collapse and misleading self-reflection, and a lack of synthesis capabilities that prevents leveraging complementary strengths across candidate patches. Prism adopts a coarse-to-fine paradigm across three stages — Global Exploration, Local Exploration, and Solution Synthesis — to systematically generate, refine, and integrate diverse repair solutions. With Claude 4.6 Sonnet, Prism achieves 82.0% Pass@1 on SWE-bench Verified, setting a new state-of-the-art. Further analyses confirm that the synthesis stage uniquely resolves 15 issues that no isolated candidate could address alone.

ForeignKey db_collation inheritance failure). Live-SWE-Agent correctly fixes related.py; LingXi correctly fixes schema.py; neither alone produces a complete patch — only synthesis resolves the issue.
Limitations of Existing Work
Limitation 1 — Lack of Solution Diversity & Misleading Self-Reflection
RLHF-fine-tuned models exhibit mode collapse, producing semantically homogeneous solutions even under high-temperature sampling. Simultaneously, erroneous self-reflection feedback causes agents (e.g., Trae, JoyCode) to abandon correct reasoning paths and converge prematurely on incorrect, repetitive patches.
Limitation 2 — Lack of Solution Synthesis Capabilities
Existing frameworks evaluate candidates in isolation via ranking or voting, discarding complementary partial solutions. Complex issues (e.g., Django #33413) require coordinated multi-file modifications — no single agent covers all critical dimensions, yet no mechanism exists to synthesize their complementary strengths.